Le modalità attraverso le quali gestire gli outliers durante l’analisi dei dati non sempre sono applicate correttamente.
In questo post cerchiamo di capire come fare per evitare di avere risultati biased oppure perdere parte delle informazioni contenute nelle nostre sperimentazioni.
Quando eliminare gli outliers?
I tuoi outliers vanno eliminati, senza perdere un secondo di tempo, nel momento in cui è evidente che ci sia un problema di correttezza di raccolta o di reporting del dato. Ad esempio, se hai a che fare con la variabile “età” e dopo aver graficato i tuoi dati ti accorgi di avere un soggetto di 172 anni è evidente che quel dato non può essere utilizzato nell’analisi.
Quello che puoi eventualmente fare è cercare di risalire al valore corretto del dato. Senza sapere ne leggere ne scrivere, quel “172 anni” dovrebbe essere ragionevolmente o 17 o 72.
Per quanto mi riguarda, questo è l’unico caso in cui porsi il problema dell’utilizzo o meno dell’outlier. In tutti gli altri casi il lavoro da fare è “studiare” il dato ponendosi precise domande:
il dato influenza le assunzioni o il tipo di analisi che sto per condurre?
il dato crea un’associazione statistica che senza di esso non comparirebbe?
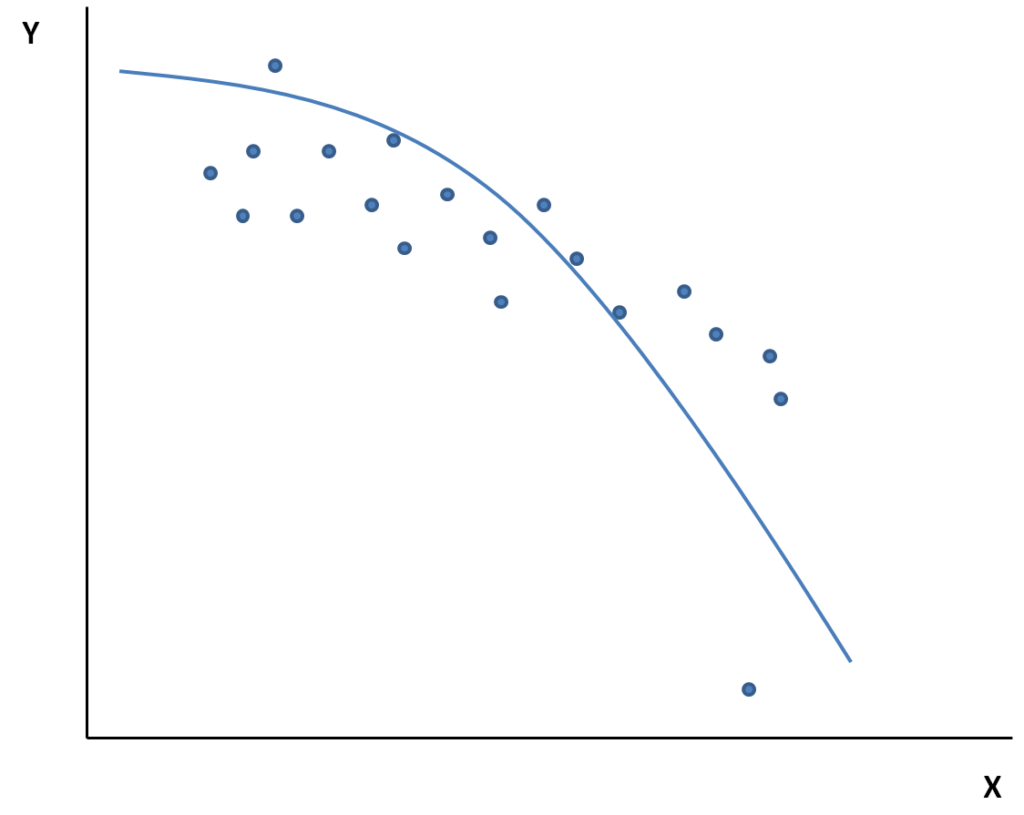
Prendiamo il caso di seguito riportato.

C’è un ipotetico outlier, in basso a destra.
In questo caso è evidente che, escludendo l’outlier, i dati possano essere modellizzati da una semplice retta con pendenza negativa (linea tratteggiata rossa). Introducendo l’outlier nell’analisi e mantenendo l’assunzione di linearità, è chiaro che andremmo ad avere un risultato fortemente biased dall’outlier (linea tratteggiata verde), in cui cioè il valore della tua Y calerà molto di più all’aumentare di X. Per supportare questo in modo più “formale” puoi anche condurre un’analisi del “leverage” del dato, un’analisi che ti indica quanto i parametri stimati dalla tua analisi dipendono dall’ipotetico outlier, di cui magari scriverò un articolo ad hoc.
La strategia è: analizzare i dati con il tuo modello lineare escludendo l’outlier e analizzare il dataset completo del suo outlier con un altro modello. Nel nostro esempio quasi certamente un modello esponenziale dovrebbe fare un buon lavoro, come indicato dalla linea tratteggiata azzurra della seguente figura.
In alcuni casi è ancora più evidente che la significatività statistica del test che hai utilizzato è conferita dalla presenza dell’outlier, come puoi vedere nella figura sotto.
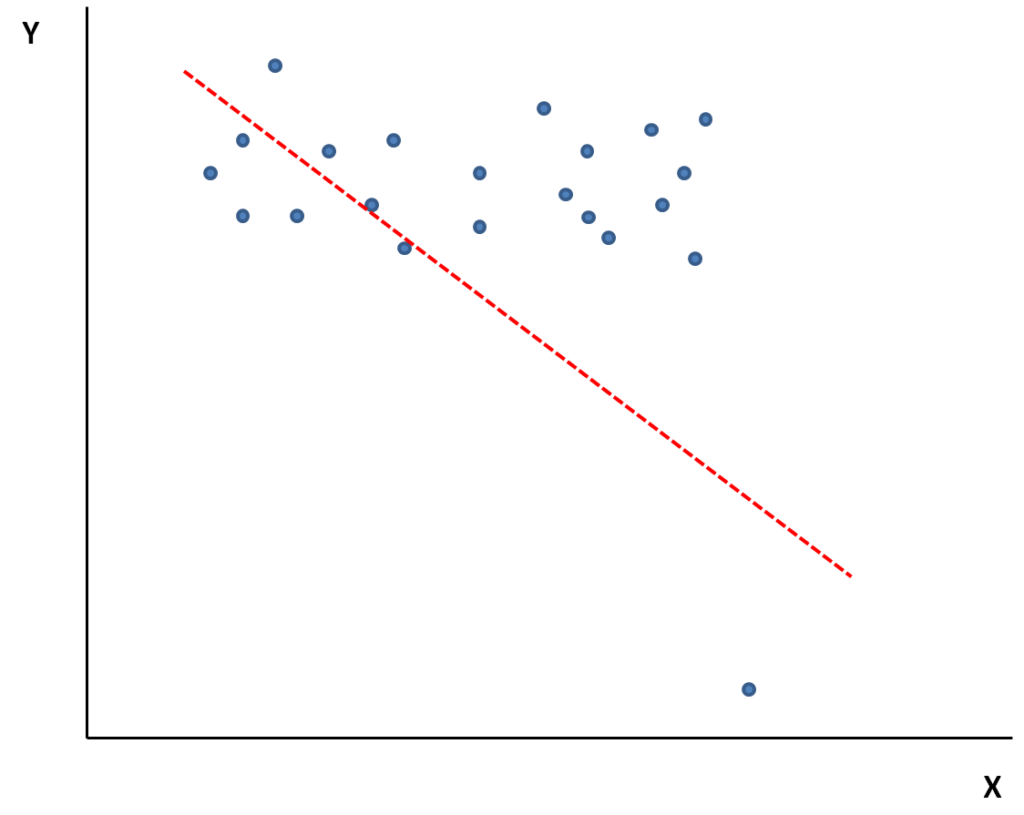 Si tratta di un’esasperazione del caso visto prima dove la linea verde accentua un’associzione statistica più lieve, ma quasi certamente presente.
Si tratta di un’esasperazione del caso visto prima dove la linea verde accentua un’associzione statistica più lieve, ma quasi certamente presente.
In questo caso è evidente che la pendenza della linea e la presenza di un’associazione è dovuta esclusivamente alla presenza dell’outlier.
La strategia in questo caso è rimuovere l’outlier senza poi andare a fare lo sforzo di modellizzare i dati in un altro modo (non c’è niente da modellizzare: è evidente che il valore di Y non camba al variare del valore di X).
Anche in questo caso, tuttavia, rimane buona pratica quella di comunicare la presenza di questo outlier nei risultati dello studio, o comunque nei materiali supplementari.
Ciao!
Gianfranco
Ti serve aiuto? Contattaci
[contact-form-7 id=”140″ title=”Modulo di contatto 1″]
[/one_half]
[/columns]
[recent_posts number_of_columns=”e.g. 4″ number_of_posts=”e.g. 4″]