Hai condotto una sperimentazione e hai raccolto anche i valori di baseline del tuo endpoint.
Fantastico. Utilissimo. Avere misure di baseline è sempre utile, sia nel caso di studi osservazionali che nei trial randomizzati.
Tuttavia….
Tuttavia, molti ricercatori utilizzano queste misurazioni in modo non corretto, o comunque non nel migliore dei modi.
In questo post cerchiamo di capire quale sia il modo di utilizzare i valori di baseline nell’analisi dei nostri dati, e lo facciamo attraverso guardando a 3 aspetti sui quali spesso vedo i ricercatori fare confusione.
Prima però bisogna fare una premessa:
per evitare di essere dispersivi in questo articolo consideriamo solo il caso dei trial randomizzati. Per gli studi osservazionali mi riprometto di scriverne in futuro.
Usare il baseline come covariate in un modello ANCOVA (e non per calcolare il “change from baseline”)
Prendiamo il più classico degli esempi, quello in cui randomizzi i tuo pazienti in due bracci: farmaco A e farmaco B.
Il tuo endpoint è la glicemia dopo 4 ore dal trattamento.
E diciamo che ad ognuno dei tuoi pazienti, prima di sottoporli a trattamento, misuri la glicemia di baseline (o “basale”, come si usa dire nella pratica clinica e di laboratorio).
Come usiamo questo valore di baseline?
Hai 3-4 possibilità.
- Fai il tuo t-test solo sull’outcome, cioè sul valore di glicemia dopo 4 ore senza usare il baseline.
- Fai il tuo test sui change from baseline (cioè “glicemia dopo 4 ore – (meno) glicemia al baseline”).
- Utilizzi un modello di analisi della covarianza (ANCOVA) in cui: la tua variabile dipendente “la Y per capirci) è la glicemia dopo 4 ore; i predittori (le “X” per capirci) sono il trattamento (cioè farmaco A oppure farmaco B), il valore di baseline ed eventualmente altre covariate che si presume possano andare a determinare il valore del tuo outcome (esempio: sesso ed età).
- Calcoli l’incremento percentuale della glicemia per i tuoi due gruppi e fai un bel test tra i due incrementi.
Qual è il metodo migliore?
Il numero 3. L’ analisi della covarianza è quello che da maggiore precisione rispetto alle opzioni 1 e 2. La 4 non la considerare nemmeno.
A tal proposito a fine articolo faccio un piccolo approfondimento a riguardo delle prestazioni di ANCOVA rispetto agli altri metodi.
Ma andiamo avanti; ti parlavo di tre aspetti critici. Andiamo a vedere il secondo…
Non testare la differenza del valore di baseline tra i bracci dello studio
Siamo in uno studio randomizzato, non te lo scordare. Riportare un t-test tra due gruppi costruiti dal caso (dalla randomizzazione) vuol dire andare a stimare l’effetto…del caso! Se ci pensi è un controsenso. Devi avere un motivo per fare un test del genere: è andato storto qualcosa in fase di randomizzazione o di allocazione dei soggetti? Se hai un’ipotesi del genere allora ha senso, in caso contrario no.
Attenzione all’uso delle interazioni del baseline con il trattamento
Diciamo che tu sospetta che nel tuo esperimento l’effetto del trattamento dipenda dal valore di baseline. Nell’esempio che abbiamo fatto prima che uno dei due farmaci A e B funzioni meglio rispetto all’altro ma a seconda dei livelli di glicemia basale.
Qua ci sono un po’ di criticità di cui tenere conto perché valutare l’interazione tra baseline e trattamento richiede molta cautela:
per vedere un effetto di interazione serve un sample size più alto rispetto alla stima del singolo effetto principale per cui dovresti aver disegnato lo studio ad hoc per l’analisi dell’interazione (e io in tanti anni un ostudio così non l’ho mai visto);
possono subentrare problemi di interpretazione dei valori di interazione (soprattutto se non hai esperienza come statistico) e quasi sempre occorre standardizzare il baseline (ad esempio, come spiegavo in un post precedente, attraverso l’operazione di “centratura”);
l’esplorazione dell’interazione è sacrosanta, ma non solitamente come analisi principale nel tuo protocollo; nelle linee guida degli enti regolatori (come ad esempio questa dell’European Medicines Agency ) vedremmo che l’analisi principale di un trial non dovrebbe comprendere questo effetto di interazione. Eventualmente puoi dichiarare nel protocollo che effettuerai delle analisi di sensitività successive in cui esplorerai appunto l’interazione outcome-baseline.
Un approfondimento finale
Come ti dicevo, potrebbe essere di tuo interesse un approfondimento sul perché dell’utilizzo dell’analisi ANCOVA per l’introduzione del baseline nell’analisi.
Intanto, come accennato sopra, ANCOVA è più precisa rispetto agli altri metodi. Tradotto: intervalli di confidenza più stretti o, in altri termini, una minore varianza della stima.
Questa variabilità dipende ovviamente da un altro fattore: dalla correlazione esistente tra baseline e outcome, nel tuo caso tra glicemia basale e glicemia dopo 4 ore dal trattamento.
Spieghiamoci: se baseline e outcome sono molto correlati (coefficiente di correlazione tendente all’uno) capisci bene quanto sia importante “ripulire” la stima del trattamento dall’effetto del baseline. Per valori di correlazione più bassi, invece, il problema è di dimensioni più contenute.
Ti riporto sotto una breve rappresentazione grafica di come cambia la precisione della tua stima al variare del metodo, della correlazione outcome-baseline, a parità di altre condizioni. Si tratta di una riproduzione di quanto trovi in un testo dello statistico britannico Stephen Senn, “Statistical Issues in Drug Development”, una delle bibbie della statistica per i clinical trials.
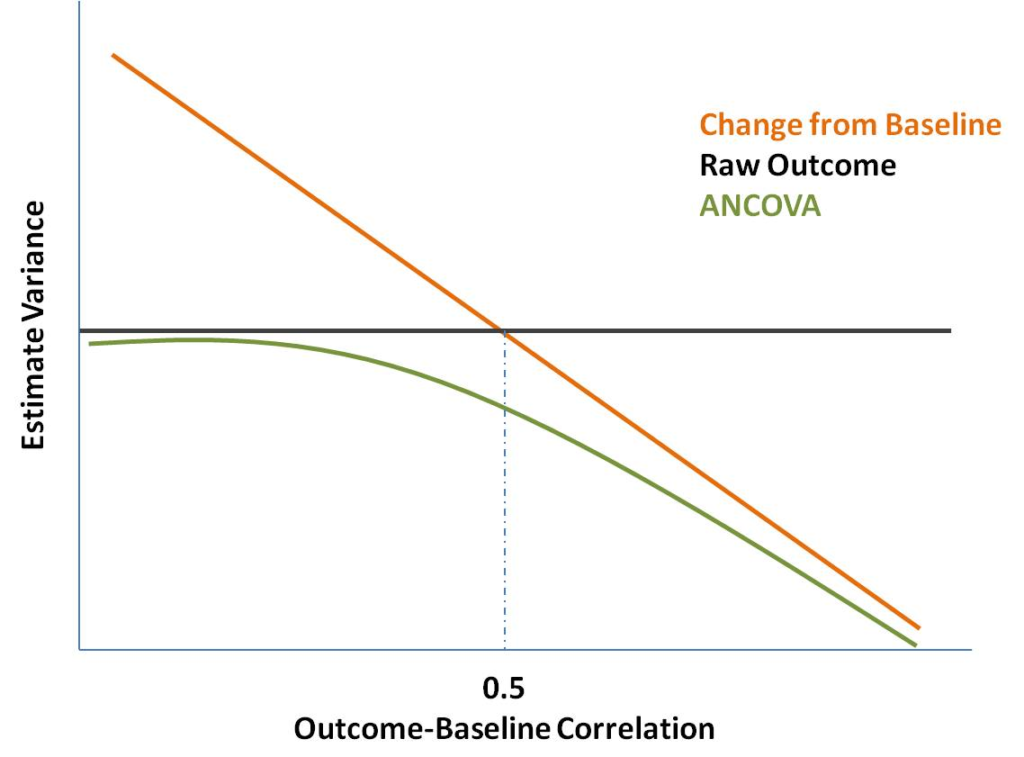
Cosa succede esattamente in questo grafico che ho maldestramente riprodotto?
Il grafico ti dice chiaramente che se consideriamo come riferimento la varianza della stima del trattamento ottenuto confrontando gli outcome grezzi (nel nostro esempio “glicemia a 4 ore dal trattamento”) , l’utilizzo del “change from baseline” ti conferisce un guadagno di precisione per correlazione outcome-baseline sopra 0.5, mentre l’ANCOVA è mediamente sempre più precisa rispetto agli altri due metodi.
Andiamo oltre. Sul fatto che ci siano delle assunzioni da rispettare per l’analisi della covarianza ne parliamo in un altro post. Nel frattempo sappi che per la stima del tuo trattamento, in generale, l’ANCOVA è decisamente stabile nonostante il traballare delle assunzioni.
Infine, due parole sull’opzione 4, “uso della variazione percentuale”. Questo metodo è assolutamente da sconsigliare per motivi distribuzionali che non è il caso di approfondire ora. Al limite, se proprio non ne puoi fare a meno, limitati ad utilizzare queste misure in modo puramente descrittivo.
Spero tutto sia chiaro.
Nel caso così non fosse ricordati che puoi chiedere chiarimenti alla mail info@statsimprove.com
Ti serve aiuto? Contattaci e ti forniremo una soluzione.
La nostra struttura di network di professionisti ci permette di abbattere notevolmente i costi dei servizi di supporto e darne accesso, oltre che alle aziende, anche a gruppi di ricerca universitaria e studenti.
[contact-form-7 id=”140″ title=”Modulo di contatto 1″]